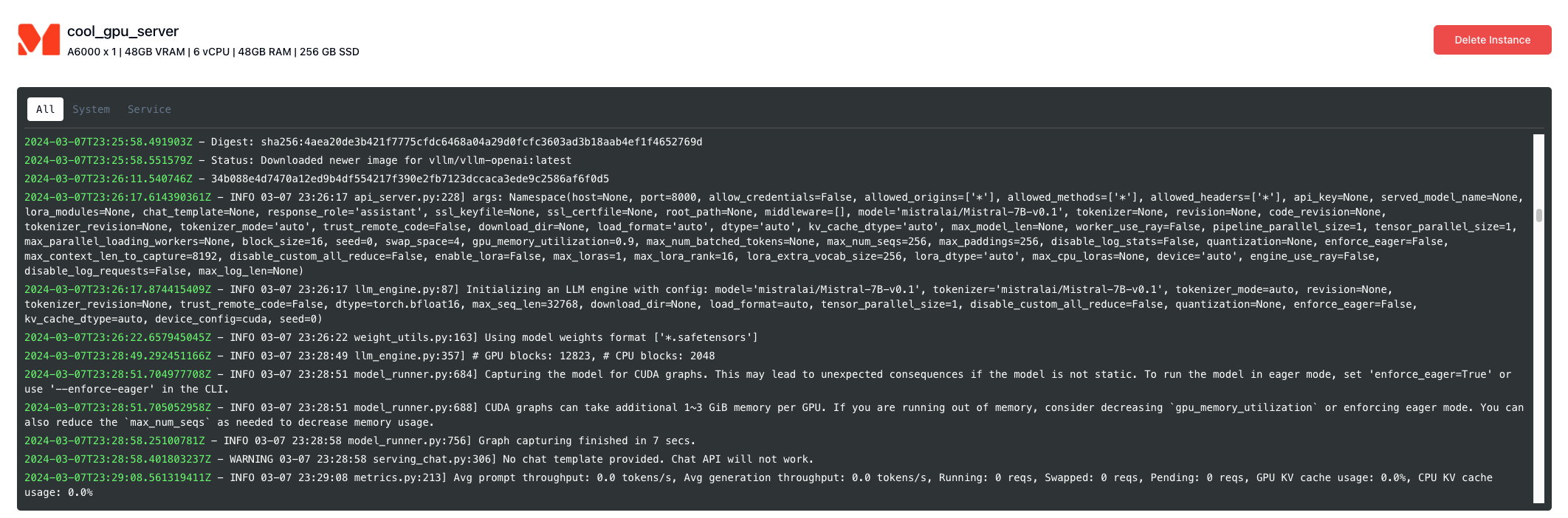
#Wait until the previous cell has an IP address associated with it, and then add a few minutes for the vLLM server to stand up.
#It is usually best to look at the logs on the dashboard to tell when the model is loaded.
model_list_response = requests.get(f'http://{ip_addr}:8000/v1/models')
print(model_list_response.text)
vllm_headers = {
'Content-Type': 'application/json',
}
json_data = {
'model': model_id,
'prompt': 'San Francisco is a',
'max_tokens': 7,
'temperature': 0,
}
completion_response = requests.post(f'http://{ip_addr}:8000/v1/completions', headers=vllm_headers, json=json_data)
print(completion_response.text)