Benchmarking Models
With the Container Launch config, we can spin up a secure VM, and start a container on it automatically. Let’s start with a very simple example - running evals on a new model from Huggingface. We have an image that does this with the LM Eval Harness library using HF Transformers. The code for it can be found and forked here. We also have a notebook that automatically launches this image on the most affordable A6000’s on the market to run the Mistral-7b-Instruct-v0.2 model though a benchmark. You can configure the model, gpu type, number of fewshot examples, and the benchmark eval.Setup
The requirements are simple, so in your preferred python environment:deploy_container.ipynb you will need to input two things: 1. Your Shadeform API Key from here, and 2. A huggingface_token if the model you need is gated (like Llama2 or Gemma).
The notebook kicks off a VM request and runs the container specifically on a 1xA6000 Machine which are quite afforable on our platform. The container will download the model and run the benchmark for us.
The notebook leverages a lot of the principles found in this guide for using the platform to find affordable GPU’s.
Deploying a container
Once we have an available instance, we will deploy a container that runs lm-eval-harness on the model. Here is where we pass in environment variables, and select the docker image via our API.Checking Results via the Shadeform Platform
The first way to check the results is by watching the logs under “Running Instances”, clicking our instance, and then the Logs(beta) tab. Here we see a stream of the logs from the docker container. When it is done, it will look something like this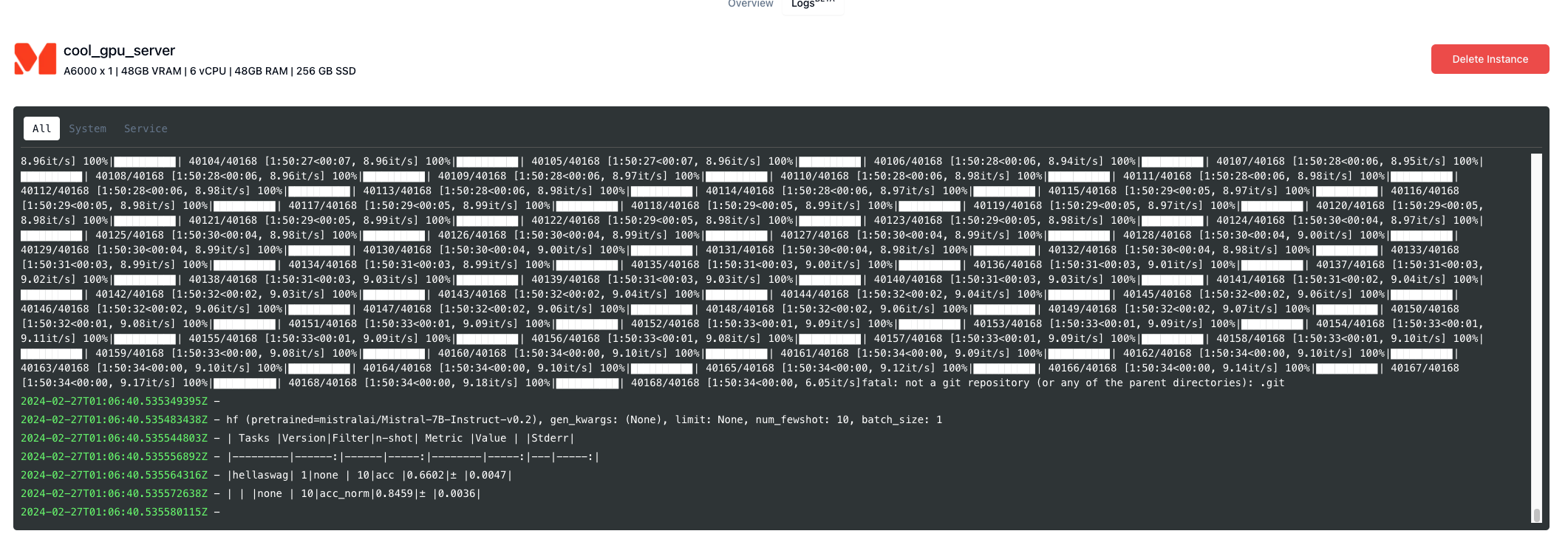
Checking Results inside your IDE
At the bottom of the notebook, there is a cell that prints out the IP address of your instance.ssh into the instance by leveraging this ip address and our shadeform .pem file.
-a flag is if it has already finished.